Lesson 1. Compare Lidar With Human Measured Tree Heights - Remote Sensing Uncertainty
Lidar Compared to Human Measurements: Uncertainty and Remote Sensing Data - Intermediate earth data science textbook course module
Welcome to the first lesson in the Lidar Compared to Human Measurements: Uncertainty and Remote Sensing Data module. Uncertainty quantifies the range of values within which the value of the measurement falls - within a specified level of confidence. Learn about the concept of uncertainty as it relates to both remote sensing and other spatial data.Chapter Six - Uncertainty in Remote Sensing Data
In this chapter, you will integrate vector and raster data using Python to explore uncertainty in scientific analyses.
Learning Objectives
After completing this chapter, you will be able to:
- List and describe at least 3 sources of uncertainty / error associated with remote sensing data.
- Interpret a scatter plot that compares remote sensing values with field measured values to determine how “well” the two metrics compare.
- Use the
rasterstats.zonal_stats()function to extract raster pixel values using a vector extent or set of extents. - Create a scatter plot with a one to one line in Python using matplotlib.
- Merge two dataframes in Python.
- Perform a basic least squares linear regression analysis on two variables of interest in Python.
- Analyze regression outputs to determine the strength of the relatonship between two variables.
- Define
R-squaredandp-valueas it relates to regression.
What You Need
You will need a computer with internet access to complete this lesson. You will also need the data you downloaded for last week of this class: spatial-vector-lidar data subset.
Download Spatial Lidar Teaching Data Subset data
or using the earthpy package: et.data.get_data("spatial-vector-lidar")
Understand Uncertainty and Error
It is important to consider error and uncertainty when presenting scientific results. Most measurements that we make - be they from instruments or humans - have uncertainty associated with them. We will discuss what that means, below.
Uncertainty
Uncertainty: Uncertainty quantifies the range of values within which the value of the measure falls within - within a specified level of confidence. The uncertainty quantitatively indicates the “quality” of your measurement. It answers the question: “how well does the result represent the value of the quantity being measured?”
Tree Height Measurement Example
So for example let’s pretend that we measured the height of a tree 10 times. Each time our tree height measurement may be slightly different? Why? Because maybe each time we visually determined the top of the tree to be in a slightly different place. Or maybe there was wind that day during measurements that caused the tree to shift as we measured it yielding a slightly different height each time. or… what other reasons can you think of that might impact tree height measurements?

What is the True Value?
So you may be wondering, what is the true height of our tree? In the case of a tree in a forest, it’s very difficult to determine the true height. So we accept that there will be some variation in our measurements and we measure the tree over and over again until we understand the range of heights that we are likely to get when we measure the tree.
/opt/conda/envs/EDS/lib/python3.8/site-packages/rasterio/plot.py:263: SyntaxWarning: "is" with a literal. Did you mean "=="?
if len(arr.shape) is 2:

In the example above, the mean tree height value is towards the center of the distribution of measured heights. You might expect that the sample mean of our observations provides a reasonable estimate of the true value. The variation among our measured values may also provide some information about the precision (or lack thereof) of the measurement process.
Read more about the what a box plots tells you about data.

Measurement Accuracy
Measurement accuracy is a concept that relates to whether there is bias in measurements, i.e. whether the expected value of our observations is close to the true value. For low accuracy measurements, we may collect many observations, and the mean of those observations may not provide a good measure of the truth (e.g., the height of the tree). For high accuracy measurements, the mean of many observations would provide a good measure of the true value. This is different from precision, which typically refers to the variation among observations. Accuracy and precision are not always tightly coupled. It is possible to have measurements that are very precise but inaccurate, very imprecise but accurate, etc.

Systematic vs random error
Systematic Error: a systematic error is one that tends to shift all measurements in a systematic way. This means that the mean value of a set of measurements is consistently displaced or varied in a predictable way, leading to inaccurate observations. Causes of systematic errors may be known or unknown but should always be corrected for when present. For instance, no instrument can ever be calibrated perfectly, so when a group of measurements systematically differ from the value of a standard reference specimen, an adjustment in the values should be made. Systematic error can be corrected for only when the “true value” (such as the value assigned to a calibration or reference specimen) is known.
Example: Remote sensing instruments need to be calibrated. For example a laser in a lidar system may be tested in a lab to ensure that the distribution of output light energy is consistent every time the laser “fires”.
Random Error: is a component of the total error which, in the course of a number of measurements, varies in an unpredictable way. It is not possible to correct for random error. Random errors can occur for a variety of reasons such as:
- Lack of equipment sensitivity. An instrument may not be able to respond to or indicate a change in some quantity that is too small or the observer may not be able to discern the change.
- Noise in the measurement. Noise is extraneous disturbances that are unpredictable or random and cannot be completely accounted for.
- Imprecise definition. It is difficult to exactly define the dimensions of a object. For example, it is difficult to determine the ends of a crack with measuring its length. Two people may likely pick two different starting and ending points.
Example: Random error may be introduced when we measure tree heights as discussed above.
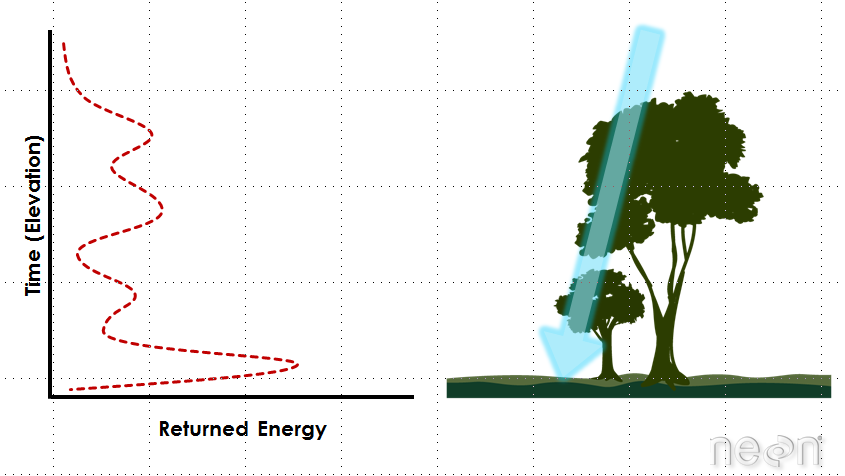
Use Lidar to Estimate Tree Height
Lidar data can be used estimate tree height because it is an efficient way to measure large areas of trees (forests) quantitatively. However, you can process the lidar data in many different ways to estimate height. Which method most closely represents the actual heights of the trees on the ground?


Study Site Location
To answer the question above, let’s look at some data from a study site location in California - the San Joaquin Experimental range field site. You can see the field site location on the map below.

Study Area Plots
At this study site, we have both lidar data - specifically a canopy height model that was processed by NEON (National Ecological Observatory Network). We also have some “ground truth” data. That is we have measured tree height values collected at a set of field site plots by technicians at NEON. We will call these measured values in situ measurements.
A map of our study plots is below overlaid on top of the canopy height model.

Compare Lidar Derived Height to In Situ Measurements
We can compare maximum tree height values at each plot to the maximum pixel value
in our CHM for each plot. To do this, we define the geographic boundary of our plot
using a polygon - in the case below we use a circle as the boundary. We then extract
the raster cell values for each circle and calculate the max value for all of the
pixels that fall within the plot area.
Then, we calculate the max height of our measured plot tree height data.
Finally we compare the two using a scatter plot to see how closely the data relate. Do they follow a 1:1 line? Do the data diverge from a 1:1 relationship?


How different are the data?

View interactive scatterplot
View interactive difference barplot
Share on
Twitter Facebook Google+ LinkedIn
Leave a Comment