Lesson 3. Clean Remote Sensing Data in Python - Clouds, Shadows & Cloud Masks
Learning Objectives
- Describe the impacts of cloud cover on analysis of remote sensing data.
- Use a mask to remove portions of an spectral dataset (image) that is covered by clouds / shadows.
- Define mask / describe how a mask can be useful when working with remote sensing data.
About Landsat Scenes
Landsat satellites orbit the earth continuously collecting images of the Earth’s surface. These images, are divided into smaller regions - known as scenes.
Landsat images are usually divided into scenes for easy downloading. Each Landsat scene is about 115 miles long and 115 miles wide (or 100 nautical miles long and 100 nautical miles wide, or 185 kilometers long and 185 kilometers wide). -wikipedia
Challenges Working with Landsat Remote Sensing Data
In the previous lessons, you learned how to import a set of geotiffs that made up the bands of a Landsat raster. Each geotiff file was a part of a Landsat scene, that had been downloaded for this class by your instructor. The scene was further cropped to reduce the file size for the class.
You ran into some challenges when you began to work with the data. The biggest problem was a large cloud and associated shadow that covered your study area of interest - the Cold Springs fire burn scar.
Work with Clouds, Shadows and Bad Pixels in Remote Sensing Data
Clouds and atmospheric conditions present a significant challenge when working with multispectral remote sensing data. Extreme cloud cover and shadows can make the data in those areas, un-usable given reflectance values are either washed out (too bright - as the clouds scatter all light back to the sensor) or are too dark (shadows which represent blocked or absorbed light).
In this lesson you will learn how to deal with clouds in your remote sensing data. There is no perfect solution of course. You will just learn one approach.
import os
from glob import glob
import matplotlib.pyplot as plt
from matplotlib import patches as mpatches, colors
import seaborn as sns
import numpy as np
from numpy import ma
import xarray as xr
import rioxarray as rxr
import earthpy as et
import earthpy.plot as ep
import earthpy.mask as em
# Prettier plotting with seaborn
sns.set_style('white')
sns.set(font_scale=1.5)
# Download data and set working directory
data = et.data.get_data('cold-springs-fire')
os.chdir(os.path.join(et.io.HOME,
'earth-analytics',
'data'))
Functions To Process Landsat Data
To begin, you can use the functions created in the previous lesson to process your Landsat data.
def open_clean_band(band_path, crop_layer=None):
"""A function that opens a Landsat band as an (rio)xarray object
Parameters
----------
band_path : list
A list of paths to the tif files that you wish to combine.
crop_layer : geopandas geodataframe
A geodataframe containing the clip extent of interest. NOTE: this will
fail if the clip extent is in a different CRS than the raster data.
Returns
-------
An single xarray object with the Landsat band data.
"""
if crop_layer is not None:
try:
clip_bound = crop_layer.geometry
cleaned_band = rxr.open_rasterio(band_path,
masked=True).rio.clip(clip_bound,
from_disk=True).squeeze()
except Exception as err:
print("Oops, I need a geodataframe object for this to work.")
print(err)
else:
cleaned_band = rxr.open_rasterio(band_path,
masked=True).squeeze()
return cleaned_band
def process_bands(paths, crop_layer=None, stack=False):
"""
Open, clean and crop a list of raster files using rioxarray.
Parameters
----------
paths : list
A list of paths to raster files that could be stacked (of the same
resolution, crs and spatial extent).
crop_layer : geodataframe
A geodataframe containing the crop geometry that you wish to crop your
data to.
stack : boolean
If True, return a stacked xarray object. If false will return a list
of xarray objects.
Returns
-------
Either a list of xarray objects or a stacked xarray object
"""
all_bands = []
for i, aband in enumerate(paths):
cleaned = open_clean_band(aband, crop_layer)
cleaned["band"] = i+1
all_bands.append(cleaned)
if stack:
print("I'm stacking your data now.")
return xr.concat(all_bands, dim="band")
else:
print("Returning a list of xarray objects.")
return all_bands
Next, you will load and plot landsat data. If you are completing the earth analytics course, you have worked with these data already in your homework.
HINT: Since we are only using the RGB and the NIR bands for this exercise, you can use *band[2-5]*.tif inside glob to filter just the needed bands. This will save a lot of time in processing since you will only be using the data you need.
Note that one thing was added to the functions below - a conditional that allows you to chose to either crop or not crop your data.
landsat_dirpath_pre = os.path.join("cold-springs-fire",
"landsat_collect",
"LC080340322016070701T1-SC20180214145604",
"crop",
"*band[2-5]*.tif")
landsat_paths_pre = sorted(glob(landsat_dirpath_pre))
landsat_pre = process_bands(landsat_paths_pre, stack=True)
landsat_pre
I'm stacking your data now.
<xarray.DataArray (band: 4, y: 177, x: 246)>
array([[[ 443., 456., 446., ..., 213., 251., 293.],
[ 408., 420., 436., ..., 226., 272., 332.],
[ 356., 375., 373., ..., 261., 329., 383.],
...,
[ 407., 427., 428., ..., 306., 273., 216.],
[ 545., 552., 580., ..., 307., 315., 252.],
[ 350., 221., 233., ..., 320., 348., 315.]],
[[ 635., 641., 629., ..., 360., 397., 454.],
[ 601., 617., 620., ..., 380., 418., 509.],
[ 587., 600., 573., ..., 431., 513., 603.],
...,
[ 679., 742., 729., ..., 493., 482., 459.],
[ 816., 827., 824., ..., 461., 502., 485.],
[ 526., 388., 364., ..., 463., 501., 512.]],
[[ 625., 671., 651., ..., 265., 307., 340.],
[ 568., 620., 627., ..., 309., 354., 431.],
[ 513., 510., 515., ..., 362., 464., 565.],
...,
[ 725., 834., 864., ..., 485., 467., 457.],
[1031., 864., 844., ..., 438., 457., 429.],
[ 525., 432., 411., ..., 465., 472., 451.]],
[[2080., 1942., 1950., ..., 1748., 1802., 2135.],
[2300., 2045., 1939., ..., 1716., 1783., 2131.],
[2582., 2443., 2347., ..., 1836., 2002., 2241.],
...,
[2076., 1993., 2145., ..., 1914., 2066., 2166.],
[1910., 1899., 1962., ..., 1787., 2038., 2300.],
[1633., 1611., 1738., ..., 1714., 1848., 2194.]]], dtype=float32)
Coordinates:
* band (band) int64 1 2 3 4
* x (x) float64 4.557e+05 4.557e+05 4.557e+05 ... 4.63e+05 4.63e+05
* y (y) float64 4.428e+06 4.428e+06 ... 4.423e+06 4.423e+06
spatial_ref int64 0
Attributes:
STATISTICS_MAXIMUM: 8481
STATISTICS_MEAN: 664.90340361031
STATISTICS_MINIMUM: -767
STATISTICS_STDDEV: 1197.873301452
scale_factor: 1.0
add_offset: 0.0- band: 4
- y: 177
- x: 246
- 443.0 456.0 446.0 475.0 ... 1.706e+03 1.714e+03 1.848e+03 2.194e+03
array([[[ 443., 456., 446., ..., 213., 251., 293.], [ 408., 420., 436., ..., 226., 272., 332.], [ 356., 375., 373., ..., 261., 329., 383.], ..., [ 407., 427., 428., ..., 306., 273., 216.], [ 545., 552., 580., ..., 307., 315., 252.], [ 350., 221., 233., ..., 320., 348., 315.]], [[ 635., 641., 629., ..., 360., 397., 454.], [ 601., 617., 620., ..., 380., 418., 509.], [ 587., 600., 573., ..., 431., 513., 603.], ..., [ 679., 742., 729., ..., 493., 482., 459.], [ 816., 827., 824., ..., 461., 502., 485.], [ 526., 388., 364., ..., 463., 501., 512.]], [[ 625., 671., 651., ..., 265., 307., 340.], [ 568., 620., 627., ..., 309., 354., 431.], [ 513., 510., 515., ..., 362., 464., 565.], ..., [ 725., 834., 864., ..., 485., 467., 457.], [1031., 864., 844., ..., 438., 457., 429.], [ 525., 432., 411., ..., 465., 472., 451.]], [[2080., 1942., 1950., ..., 1748., 1802., 2135.], [2300., 2045., 1939., ..., 1716., 1783., 2131.], [2582., 2443., 2347., ..., 1836., 2002., 2241.], ..., [2076., 1993., 2145., ..., 1914., 2066., 2166.], [1910., 1899., 1962., ..., 1787., 2038., 2300.], [1633., 1611., 1738., ..., 1714., 1848., 2194.]]], dtype=float32) - band(band)int641 2 3 4
array([1, 2, 3, 4])
- x(x)float644.557e+05 4.557e+05 ... 4.63e+05
array([455670., 455700., 455730., ..., 462960., 462990., 463020.])
- y(y)float644.428e+06 4.428e+06 ... 4.423e+06
array([4428450., 4428420., 4428390., 4428360., 4428330., 4428300., 4428270., 4428240., 4428210., 4428180., 4428150., 4428120., 4428090., 4428060., 4428030., 4428000., 4427970., 4427940., 4427910., 4427880., 4427850., 4427820., 4427790., 4427760., 4427730., 4427700., 4427670., 4427640., 4427610., 4427580., 4427550., 4427520., 4427490., 4427460., 4427430., 4427400., 4427370., 4427340., 4427310., 4427280., 4427250., 4427220., 4427190., 4427160., 4427130., 4427100., 4427070., 4427040., 4427010., 4426980., 4426950., 4426920., 4426890., 4426860., 4426830., 4426800., 4426770., 4426740., 4426710., 4426680., 4426650., 4426620., 4426590., 4426560., 4426530., 4426500., 4426470., 4426440., 4426410., 4426380., 4426350., 4426320., 4426290., 4426260., 4426230., 4426200., 4426170., 4426140., 4426110., 4426080., 4426050., 4426020., 4425990., 4425960., 4425930., 4425900., 4425870., 4425840., 4425810., 4425780., 4425750., 4425720., 4425690., 4425660., 4425630., 4425600., 4425570., 4425540., 4425510., 4425480., 4425450., 4425420., 4425390., 4425360., 4425330., 4425300., 4425270., 4425240., 4425210., 4425180., 4425150., 4425120., 4425090., 4425060., 4425030., 4425000., 4424970., 4424940., 4424910., 4424880., 4424850., 4424820., 4424790., 4424760., 4424730., 4424700., 4424670., 4424640., 4424610., 4424580., 4424550., 4424520., 4424490., 4424460., 4424430., 4424400., 4424370., 4424340., 4424310., 4424280., 4424250., 4424220., 4424190., 4424160., 4424130., 4424100., 4424070., 4424040., 4424010., 4423980., 4423950., 4423920., 4423890., 4423860., 4423830., 4423800., 4423770., 4423740., 4423710., 4423680., 4423650., 4423620., 4423590., 4423560., 4423530., 4423500., 4423470., 4423440., 4423410., 4423380., 4423350., 4423320., 4423290., 4423260., 4423230., 4423200., 4423170.]) - spatial_ref()int640
- crs_wkt :
- PROJCS["WGS 84 / UTM zone 13N",GEOGCS["WGS 84",DATUM["WGS_1984",SPHEROID["WGS 84",6378137,298.257223563,AUTHORITY["EPSG","7030"]],AUTHORITY["EPSG","6326"]],PRIMEM["Greenwich",0,AUTHORITY["EPSG","8901"]],UNIT["degree",0.0174532925199433,AUTHORITY["EPSG","9122"]],AUTHORITY["EPSG","4326"]],PROJECTION["Transverse_Mercator"],PARAMETER["latitude_of_origin",0],PARAMETER["central_meridian",-105],PARAMETER["scale_factor",0.9996],PARAMETER["false_easting",500000],PARAMETER["false_northing",0],UNIT["metre",1,AUTHORITY["EPSG","9001"]],AXIS["Easting",EAST],AXIS["Northing",NORTH],AUTHORITY["EPSG","32613"]]
- semi_major_axis :
- 6378137.0
- semi_minor_axis :
- 6356752.314245179
- inverse_flattening :
- 298.257223563
- reference_ellipsoid_name :
- WGS 84
- longitude_of_prime_meridian :
- 0.0
- prime_meridian_name :
- Greenwich
- geographic_crs_name :
- WGS 84
- horizontal_datum_name :
- World Geodetic System 1984
- projected_crs_name :
- WGS 84 / UTM zone 13N
- grid_mapping_name :
- transverse_mercator
- latitude_of_projection_origin :
- 0.0
- longitude_of_central_meridian :
- -105.0
- false_easting :
- 500000.0
- false_northing :
- 0.0
- scale_factor_at_central_meridian :
- 0.9996
- spatial_ref :
- PROJCS["WGS 84 / UTM zone 13N",GEOGCS["WGS 84",DATUM["WGS_1984",SPHEROID["WGS 84",6378137,298.257223563,AUTHORITY["EPSG","7030"]],AUTHORITY["EPSG","6326"]],PRIMEM["Greenwich",0,AUTHORITY["EPSG","8901"]],UNIT["degree",0.0174532925199433,AUTHORITY["EPSG","9122"]],AUTHORITY["EPSG","4326"]],PROJECTION["Transverse_Mercator"],PARAMETER["latitude_of_origin",0],PARAMETER["central_meridian",-105],PARAMETER["scale_factor",0.9996],PARAMETER["false_easting",500000],PARAMETER["false_northing",0],UNIT["metre",1,AUTHORITY["EPSG","9001"]],AXIS["Easting",EAST],AXIS["Northing",NORTH],AUTHORITY["EPSG","32613"]]
- GeoTransform :
- 455655.0 30.0 0.0 4428465.0 0.0 -30.0
array(0)
- STATISTICS_MAXIMUM :
- 8481
- STATISTICS_MEAN :
- 664.90340361031
- STATISTICS_MINIMUM :
- -767
- STATISTICS_STDDEV :
- 1197.873301452
- scale_factor :
- 1.0
- add_offset :
- 0.0
# Plot the data
ep.plot_rgb(landsat_pre.values,
rgb=[2, 1, 0],
title="Landsat True Color Composite Image | 30 meters \n Post Cold Springs Fire \n July 8, 2016")
plt.show()

Notice in the data above there is a large cloud in your scene. This cloud will impact any quantitative analysis that you perform on the data. You can remove cloudy pixels using a mask. Masking “bad” pixels:
- Allows you to remove them from any quantitative analysis that you may perform such as calculating NDVI.
- Allows you to replace them (if you want) with better pixels from another scene. This replacement if often performed when performing time series analysis of data. The following lesson will teach you have to replace pixels in a scene.
Cloud Masks in Python
You can use the cloud mask layer to identify pixels that are likely to be clouds
or shadows. You can then set those pixel values to masked so they are not included in
your quantitative analysis in Python.
When you say “mask”, you are talking about a layer that “turns off” or sets to nan,
the values of pixels in a raster that you don’t want to include in an analysis.
It’s very similar to setting data points that equal -9999 to nan in a time series
data set. You are just doing it with spatial raster data instead.
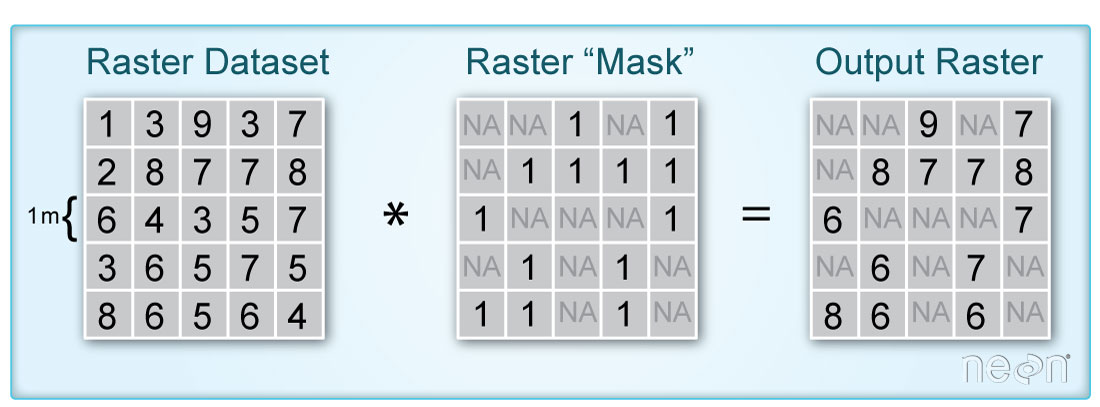
The code below demonstrated how to mask a landsat scene using the pixel_qa layer.
Raster Masks for Remote Sensing Data
Many remote sensing data sets come with quality layers that you can use as a mask
to remove “bad” pixels from your analysis. In the case of Landsat, the mask layers
identify pixels that are likely representative of cloud cover, shadow and even water.
When you download Landsat 8 data from Earth Explorer, the data came with a processed
cloud shadow / mask raster layer called landsat_file_name_pixel_qa.tif.
Just replace the name of your Landsat scene with the text landsat_file_name above.
For this class the layer is:
LC80340322016189-SC20170128091153/crop/LC08_L1TP_034032_20160707_20170221_01_T1_pixel_qa_crop.tif
You will explore using this pixel quality assurance (QA) layer, next. To begin, open
the pixel_qa layer using rioxarray and plot it with matplotlib.
# Open the landsat qa layer
landsat_pre_cl_path = os.path.join("cold-springs-fire",
"landsat_collect",
"LC080340322016070701T1-SC20180214145604",
"crop",
"LC08_L1TP_034032_20160707_20170221_01_T1_pixel_qa_crop.tif")
landsat_qa = rxr.open_rasterio(landsat_pre_cl_path).squeeze()
high_cloud_confidence = em.pixel_flags["pixel_qa"]["L8"]["High Cloud Confidence"]
cloud = em.pixel_flags["pixel_qa"]["L8"]["Cloud"]
cloud_shadow = em.pixel_flags["pixel_qa"]["L8"]["Cloud Shadow"]
all_masked_values = cloud_shadow + cloud + high_cloud_confidence
# Mask the data using the pixel QA layer
landsat_pre_cl_free = landsat_pre.where(~landsat_qa.isin(all_masked_values))
First, plot the pixel_qa layer in matplotlib.
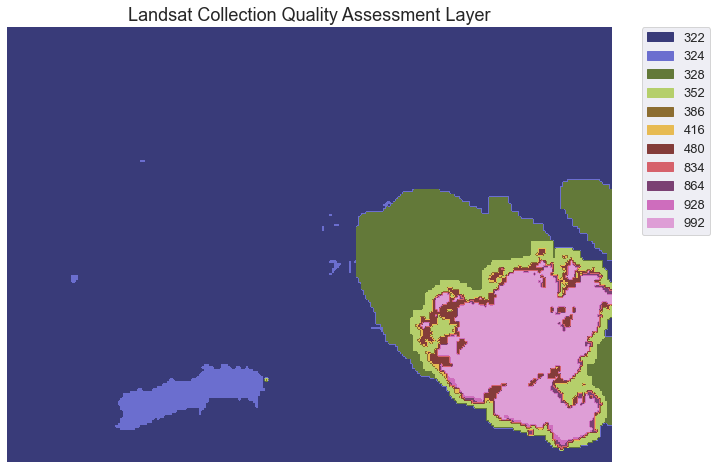
In the image above, you can see the cloud and the shadow that is obstructing our landsat image. Unfortunately for you, this cloud covers a part of your analysis area in the Cold Springs Fire location. There are a few ways to handle this issue. We will look at one: simply masking out or removing the cloud for your analysis, first.
To remove all pixels that are cloud and cloud shadow covered we need to first determine what each value in our qa raster represents. The table below is from the USGS landsat website. It describes what all of the values in the pixel_qa layer represent.
We are interested in
- cloud shadow
- cloud and
- high confidence cloud
Note that your specific analysis may require a different set of masked pixels. For instance, your analysis may require you identify pixels that are low confidence clouds too. We are just using these classes for the purpose of this class.
| Attribute | Pixel Value |
|---|---|
| Fill | 1 |
| Clear | 322, 386, 834, 898, 1346 |
| Water | 324, 388, 836, 900, 1348 |
| Cloud Shadow | 328, 392, 840, 904, 1350 |
| Snow/Ice | 336, 368, 400, 432, 848, 880, 912, 944, 1352 |
| Cloud | 352, 368, 416, 432, 480, 864, 880, 928, 944, 992 |
| Low confidence cloud | 322, 324, 328, 336, 352, 368, 834, 836, 840, 848, 864, 880 |
| Medium confidence cloud | 386, 388, 392, 400, 416, 432, 900, 904, 928, 944 |
| High confidence cloud | 480, 992 |
| Low confidence cirrus | 322, 324, 328, 336, 352, 368, 386, 388, 392, 400, 416, 432, 480 |
| High confidence cirrus | 834, 836, 840, 848, 864, 880, 898, 900, 904, 912, 928, 944, 992 |
| Terrain occlusion | 1346, 1348, 1350, 1352 |
To better understand the values above, create a better map of the data. To do that you will:
- classify the data into x classes where x represents the total number of unique values in the
pixel_qaraster. - plot the data using these classes.
We are reclassifying the data because matplotlib colormaps will assign colors to values along a continuous gradient. Reclassifying the data allows us to enforce one color for each unique value in our data.
This next section shows you how to create a mask using the xarray function isin() to create a binary cloud mask layer. In this mask all pixels that you wish to remove from your analysis or mask will be set to 1. All other pixels which represent pixels you want to use in your analysis will be set to 0.
vals
[322, 324, 328, 352, 386, 416, 480, 834, 864, 928, 992]
# You can grab the cloud pixel values from earthpy
high_cloud_confidence = em.pixel_flags["pixel_qa"]["L8"]["High Cloud Confidence"]
cloud = em.pixel_flags["pixel_qa"]["L8"]["Cloud"]
cloud_shadow = em.pixel_flags["pixel_qa"]["L8"]["Cloud Shadow"]
all_masked_values = cloud_shadow + cloud + high_cloud_confidence
all_masked_values
[328,
392,
840,
904,
1350,
352,
368,
416,
432,
480,
864,
880,
928,
944,
992,
480,
992]
# Create the cloud mask
cl_mask = landsat_qa.isin(all_masked_values)
np.unique(cl_mask)
array([False, True])
Below is the plot of the reclassified raster mask.
fig, ax = plt.subplots(figsize=(12, 8))
im = ax.imshow(cl_mask,
cmap=plt.cm.get_cmap('tab20b', 2))
cbar = ep.colorbar(im)
cbar.set_ticks((0.25, .75))
cbar.ax.set_yticklabels(["Clear Pixels", "Cloud / Shadow Pixels"])
ax.set_title("Landsat Cloud Mask | Light Purple Pixels will be Masked")
ax.set_axis_off()
plt.show()

What Does the Metadata Tell You?
You just explored two layers that potentially have information about cloud cover. However what do the values stored in those rasters mean? You can refer to the metadata provided by USGS to learn more about how each layer in your landsat dataset are both stored and calculated.
When you download remote sensing data, often (but not always), you will find layers that tell us more about the error and uncertainty in the data. Often whomever created the data will do some of the work for us to detect where clouds and shadows are - given they are common challenges that you need to work around when using remote sensing data.
Create Mask Layer in Python
To create the mask this you do the following:
- Make sure you use a raster layer for the mask that is the SAME EXTENT and the same pixel resolution as your landsat scene. In this case you have a mask layer that is already the same spatial resolution and extent as your landsat scene.
- Set all of the values in that layer that are clouds and / or shadows to
True - Finally you use the
wherefunction to apply the mask layer to the xarray DataArray (or the landsat scene that you are working with in Python). all pixel locations that were flagged as clouds or shadows in your mask toNAin yourrasteror in this caserasterstack.
Mask A Landsat Scene Using Xarray
Below you mask your data in one single step. This function .where() applies the mask you created above to your xarray DataArray. To apply the mask, ensure you put a ~ in front of your mask inside the where() function. This must be done because isin() creates the mask with True values where we want False, values, and vice versa. The ~ flips all of the values inside the array.
# Mask your data using .where()
landsat_pre_cl_free = landsat_pre.where(~cl_mask)
Alternatively, you can directly input your mask values and the pixel QA layer into the mask_pixels function. This is the easiest way to mask your data! Again, this function only takes numpy arrays, so make sure to call .values on all of your xarray DataArrays that you are using as inputs into that function.
# Mask your data and create the mask using one single line of code
landsat_pre_cl_free = landsat_pre.where(~landsat_qa.isin(all_masked_values))
# Plot the data
ep.plot_bands(landsat_pre_cl_free[3],
cmap="Greys",
title="Landsat Infrared Band | 30 meters \n Post Cold Springs Fire \n July 8, 2016",
cbar=False)
plt.show()

# Plot
ep.plot_rgb(landsat_pre_cl_free,
rgb=[3, 2, 1],
title="Landsat CIR Composite Image | 30 meters \n Post Cold Springs Fire \n July 8, 2016")
plt.show()

Share on
Twitter Facebook Google+ LinkedIn
Leave a Comment